Tutte le Parole di Ghali
I tried to analyze and visualize the lyrics of Ghali's albums published between 2017 and 2020.

Ghali is one of the most famous musicians in Italy. Probably the most well-known second-generation Italian, he is seen as a reference point by many young Italians in similar situations. After starting his career as a rapper, his style evolved into pop, with influences from hip-hop, rap, and trap. He is definitely a public figure. His lexicon sounds quite rich, especially because he is able to mix verses in Italian, Arabic, English, and French, and his albums feature a wide range of international artists. With this project, I wanted to verify whether my impression of his vocabulary was accurate.

The analysis covers only Ghali's first three albums, as it took some time to clean and analyze all the texts. The first task was to gather all the lyrics. To do this, we consulted several online sources; in our opinion, the best one was RapGenius: the lyrics were well-organized and seemed to be the most accurate compared to the original tracks. Once we had collected the lyrics, we performed an initial manual "clean-up." In many cases, the same word—especially exclamations—was written differently across versions. An example? "Hey" is sometimes written with a "y," sometimes with an "i." We found several similar cases and corrected them consistently.
However, the manual revision work went beyond that. For example, the lyrics of "Jennifer" (from *DNA*, 2020) show the chorus as follows:
Oh, nari, nari, nari, ne (Wa3lach?)
Jenni-Jenni-Jennifer (I love you)
which we changed to:
Oh, nari, nari, nari, ne (Wa3lach?)
Jennifer (I love you)
In essence: although that line is indeed sung that way in the track, "Jenni-Jenni-Jennifer" is not a single word.
Once all the lyrics were reviewed, I proceeded with their tokenization using a Python library called spaCy. This library can analyze texts in various languages and transform each word into a token. For Italian, it can recognize verbs and convert them to their infinitive forms (for example, ho mangiato – I ate – is recognized as mangiare – to eat), identify nouns and adjectives and transform them into their corresponding masculine singular forms (for instance, belle, belli, bella all become bello —typically meaning beautiful or nice— after tokenization), and break down articulated prepositions into their constituent parts (for example, dal becomes da il -from the in english).
The result of tokenization is, for each track, a long list of "simplified" words. As designed, spaCy does not apply any transformations to words it does not recognize (typically, foreign words), but it attempts to interpret recognized Italian words using the grammatical rules "learned" from its training dataset. This led to some inaccuracies, which we corrected manually. For instance, the word minchia was sometimes tokenized as minchiare. This is because the registers in the training data are very different from those in Ghali's lyrics, which make extensive use of slang.
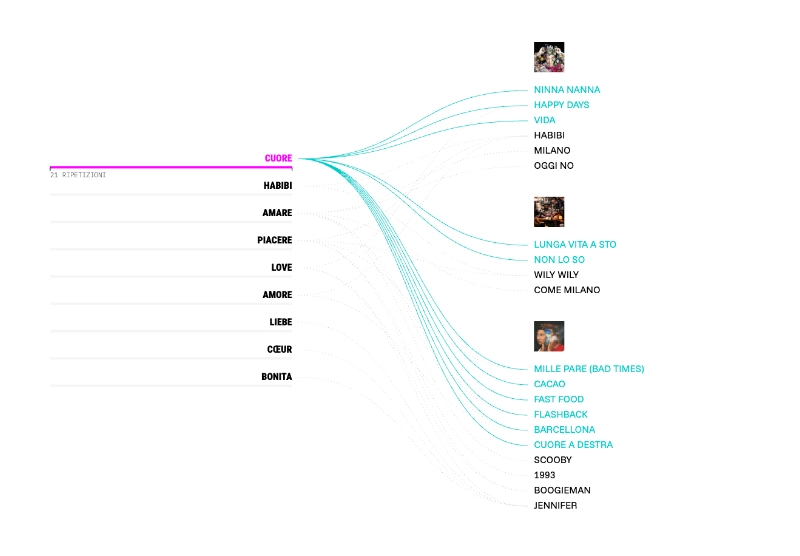
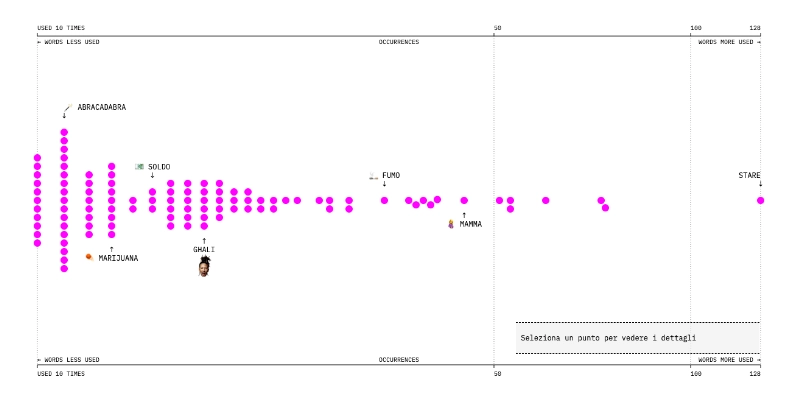
In the next phase, I wrote small programs using Node.js to count the tokens generated in the previous step and reaggregate them according to selected themes. The selection of themes was also a manual process: we read and re-read all the lyrics and created lists of words representing each theme. The result of all these steps is the database we used to generate the graphs and statistics shown on the website.
The data used by the site is static: I generated all the necessary aggregations using Node.js scripts. The UI was built using Svelte 5 and D3.js, as I wanted to be able to reuse chart components across different sections. The design is simple and bold, starting with a palette composed of only Cyan, Magenta, Yellow, and Black. I did add a darker shade of cyan for some text elements to improve readability, but everything is fundamentally based on based on that four-color palette.